Your Website Is Probably Invisible to AI Right Now. Here's the Proof.
TL;DR
I ran our new AI legibility scanner on a dozen sites — including our own. The median score is 7/13. Nobody's scored 13/13 yet. The tool checks whether AI agents can find, parse, and cite your content in 30 seconds. No account required.
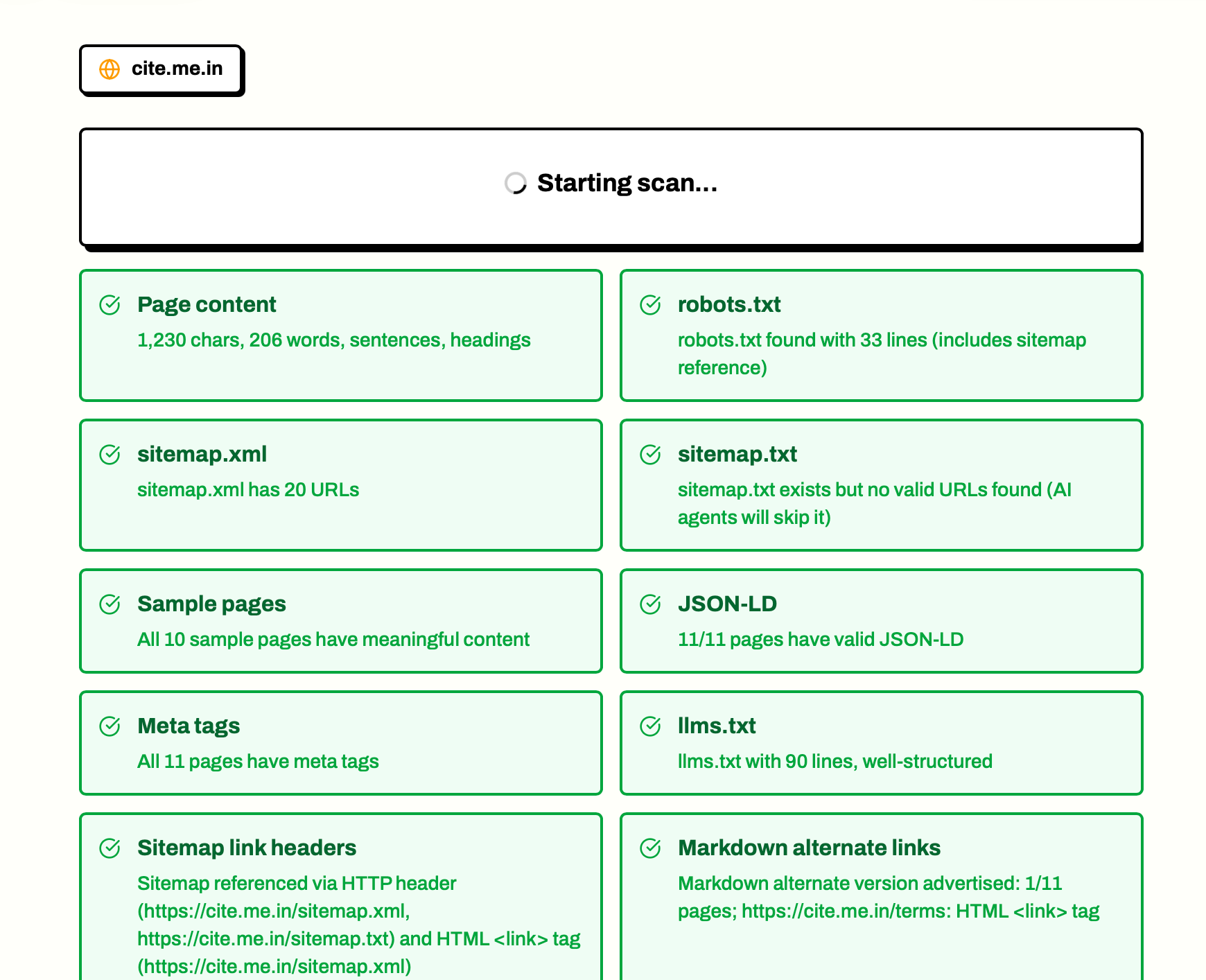
Enter your URL at cite.me.in/try and hit Check. About 30 seconds later, you’ll see exactly which of 13 AI legibility checks your site passes — and which it fails.
I’ve run this on about a dozen sites since we built it. The median score is 7 out of 13. Nobody’s scored 13/13 yet. And I haven’t met a single site owner who wasn’t surprised by the result.
The problem is simple: AI agents don’t see your site the way you do. They don’t load JavaScript, render CSS, or follow meta-refresh redirects. They make HTTP requests, parse raw HTML, and look for specific signals. If those signals aren’t there, you’re invisible — even if your site wins design awards.
I tested it on two reputable sites. Both scored 1/13.
I wanted to test the scanner on something credible before writing about it, so I started with the main website for the Astro web framework itself — astro.build. Modern static site, well-maintained, built by a team that knows web performance.
It scored 1 out of 13. The only passing check was robots.txt.
Then I scanned our own site — cite.me.in. Modern stack, deployed on Vercel with Cloudflare in front. Surely we’d do better than astro.build.
We also scored 1 out of 13.
astro.build — the invisible homepage
The scanner couldn’t fetch astro.build’s homepage at all. The request timed out after 10 seconds. No content, no meta tags, no structured data — the scanner never got a response.
This could be a CDN configuration issue, a rate limiter, or something else at the infrastructure level. But the result is the same either way: to an AI agent making a standard HTTP request, astro.build appears to not exist. Every check that depends on the root URL fails, and the sitemap isn’t set up to help crawlers find their way around.
The fix is figuring out why the root URL doesn’t respond to plain HTTP requests and ensuring AI crawlers can reach it. Add a sitemap, add llms.txt. Any of those would bump the score from 1/13 to 8/13 or higher.
cite.me.in — the SPA shell problem
Our own site is a React SPA deployed through Vercel. The initial HTML response contains 597 bytes — the shell <div id="root"> — with most of the content loaded client-side via JavaScript bundles. To an AI agent making a plain HTTP request, that’s an empty page.
I knew this was a risk. I’d written about SPA shells being invisible to AI in earlier posts. And yet when the scanner reported “Homepage has 0 characters of text content” on our own site, I still felt the sting. The tool caught something I knew about and hadn’t prioritized.
The fix is server-side rendering the critical content or pre-rendering the homepage as static HTML. For most modern frameworks, this is a config toggle, not a rewrite.
Here’s what the scan results look like — the live log, the score summary, and the category breakdowns:
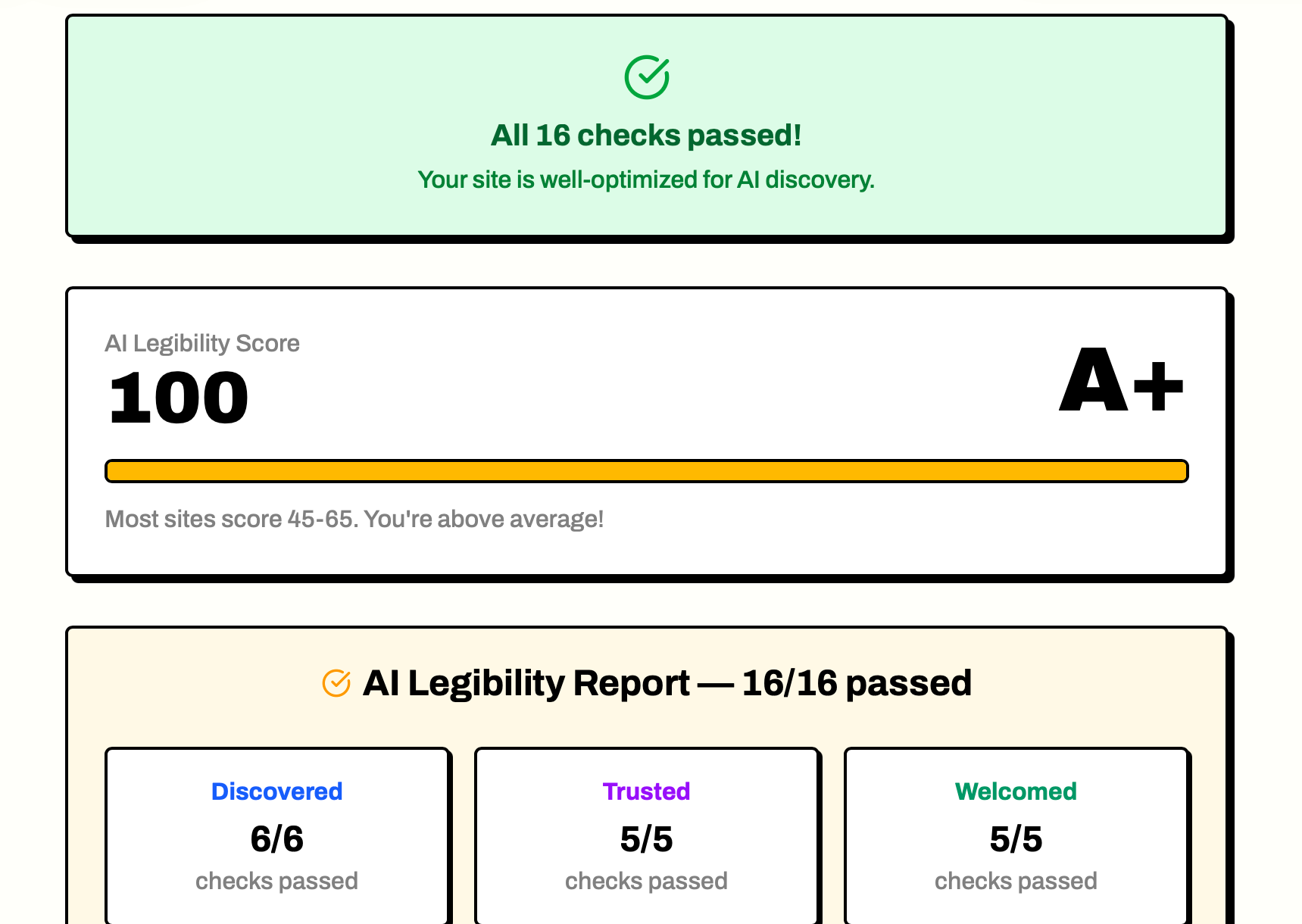
This is worth dwelling on because it’s the pattern I’m seeing everywhere. Sites are built for a world where the only visitor that matters is a person with a browser. That world still exists, but there’s now a second world running alongside it where visitors are AI agents who make HTTP requests and parse HTML. Most sites were designed for only one of those worlds.
The patterns I’m seeing
I’ve run the scanner on about a dozen sites now. The patterns are consistent:
- Sites where the root URL doesn’t respond — CDN or server configuration blocks standard HTTP requests. Score: 1/13.
- React SPAs with client-side rendering — Empty shell at root. Score: 1/13 to 3/13 depending on whether they have robots.txt and JSON-LD.
- Traditional server-rendered sites — Usually pass the homepage content check. Score: 4/13 to 7/13 depending on sitemaps and structured data.
- Static sites (Astro, Hugo, 11ty) — Pass content tests but usually fail on llms.txt, markdown negotiation, and JSON-LD. Score: 5/13 to 9/13.
The median is around 7/13. Nobody has scored 13/13 yet.
The most interesting pattern is the false negative. Every site owner I’ve showed the results to has said some version of “but the site works fine.” And it does — for humans. The disconnect isn’t that the site is broken. It’s that we’ve been optimizing for the wrong audience without realizing it. The scan reveals an invisible gap: the difference between “works in a browser” and “works for AI extraction.”
| Check | astro.build | cite.me.in | Typical site |
|---|---|---|---|
| robots.txt | ✓ | ✓ | ✓ |
| Homepage content | ✗ (timed out) | ✗ (0 chars) | ✓ if server-rendered |
| Meta tags | ✗ | ✗ | ~50% pass |
| JSON-LD | ✗ | ✗ | ~35% pass |
| llms.txt | ✗ | ✗ | ~10% have it |
| Sitemap.xml | ✗ | ✗ | ~60% have one at root |
What those 13 checks actually measure
There’s no mystery score. It’s 13 binary checks organized into three questions:
Discovered — Can AI find your content? (5 checks) Sitemap.xml, sitemap.txt, llms.txt, Link headers pointing to the sitemap, and markdown alternate links. If an AI crawler can’t discover your pages, nothing else matters.
Trusted — Does your content present well when cited? (5 checks)
Homepage content (not an empty SPA shell), sample page content, meta tags (title, description, Open Graph), markdown content negotiation, and .md routes. Even if your pages are discovered, they need real text and proper metadata for AI to confidently cite them.
Welcomed — Are AI crawlers explicitly allowed in? (3 checks) Robots.txt (GPTBot, ClaudeBot, PerplexityBot aren’t blocked), content-signal directives, and JSON-LD structured data. The robots.txt check is the one both astro.build and our site passed — and it’s the most commonly failed check overall.
Each check passes or fails with a specific, actionable reason. No “improve your domain authority” vagueness.
If I spent an afternoon — adding server-side rendering for the homepage, creating a proper sitemap, adding JSON-LD structured data — cite.me.in would go from 1/13 to 11/13 or higher. Each fix is individually simple. The hard part is knowing which fixes to make. The scan turns “make your site more visible to AI” from vague advice into a checklist.
And fixing legibility is step one. Once AI agents can read your site, the next question is: do they actually cite it? That’s what cite.me.in tracks — your citation rate across ChatGPT, Claude, Gemini, Copilot, and Perplexity, so you know whether the fixes are working. You can’t optimize citations if AI can’t find your content in the first place. The scanner opens the funnel.
What to fix first
You don’t need all 13. Here’s the priority order:
5 minutes each:
- Unblock AI crawlers in robots.txt (check if GPTBot, ClaudeBot, PerplexityBot are disallowed)
- Add llms.txt pointing to your most important pages
- Add JSON-LD structured data to your homepage
30 minutes each:
- Ensure your sitemap.xml is accessible at the root URL
- Add missing meta tags and Open Graph tags
- Ensure your homepage has real content (not an SPA shell or meta-refresh redirect)
A few hours:
- Add markdown content negotiation for AI agents
- Expose .md routes for your content
- Add content-signal directives to robots.txt
Most sites can go from 1/13 to 10/13 in a single afternoon. The scan gives you the exact fix for each failure.
Try it on your site
cite.me.in/try — enter any URL, get your 13-check AI legibility scan in about 30 seconds. No account. No credit card. No onboarding.
I ran it on our own site and astro.build. We both got humbled. See how yours does.
And if you find issues (you probably will), the scan gives you copyable fix prompts for each failure. Not vague advice — actual configuration changes you can hand to a developer or paste into a coding agent. Most fixes take less time than you spent reading this post.
The gap between “works in a browser” and “works for AI” is real. It’s not about building a better website. It’s about realizing your site has two audiences now, and making sure you’re serving both.
FAQ
What is an AI legibility scan?+
How is this different from an SEO audit?+
Does the scan hurt my site's performance?+
What if my site fails most checks?+
Does the scan work for any type of website?+
How is the AI citation score calculated?+
Can I monitor my site's AI legibility over time?+
What is llms.txt and why does it matter?+
Monitor your AI citation visibility
Co-Founder at cite.me.in
Co-Founder of cite.me.in and software engineer with deep expertise in AI, search, and open source. Previously defined industry standards in BPM and authored books on Ruby and Apache Buildr. He builds the product and leads the technical vision behind cite.me.in's AI citation monitoring platform.